
前两天装了个小工具,叫 ccusage,还有个配套给 Codex 用的 ccusage-codex,用下来感觉挺顺手,写一篇聊聊。
平时拿 Claude Code 和 Codex 写代码、改配置、查东西,时间一长心里就没底了——这个月到底花了多少?最近是不是聊太狠了?Codex 跟 Claude Code 哪个更烧钱?光靠猜只会越猜越玄,干脆找个工具老实看一眼。
搜了一圈,ccusage 刚好就是干这个的。它直接读本地 CLI 的使用日志,给你出日报、周报、月报,不用接什么后台,也不用搭监控,装完就能用。
安装一行命令搞定:
npm install -g ccusage @ccusage/codex
装好之后最常用的就这几个:
ccusage daily --offline
ccusage weekly --offline
ccusage monthly --offline
ccusage-codex daily --offline
ccusage-codex monthly --offline
ccusage-codex session --offline
我基本都带 --offline。原因很简单:ccusage-codex 默认会去 LiteLLM 拉最新定价,经常卡在 Fetching latest model pricing from LiteLLM... 那一步,半天不动。我就自己看看,又不是做账,用缓存定价够用了,快很多也稳很多。
这工具真正有意思的地方倒不是给你一个总数,而是把构成拆开了——输入多少、输出多少、缓存读了多少。Codex 那边甚至还能看到 Reasoning。一拆开,很多原本理所当然的判断马上就站不住脚了。
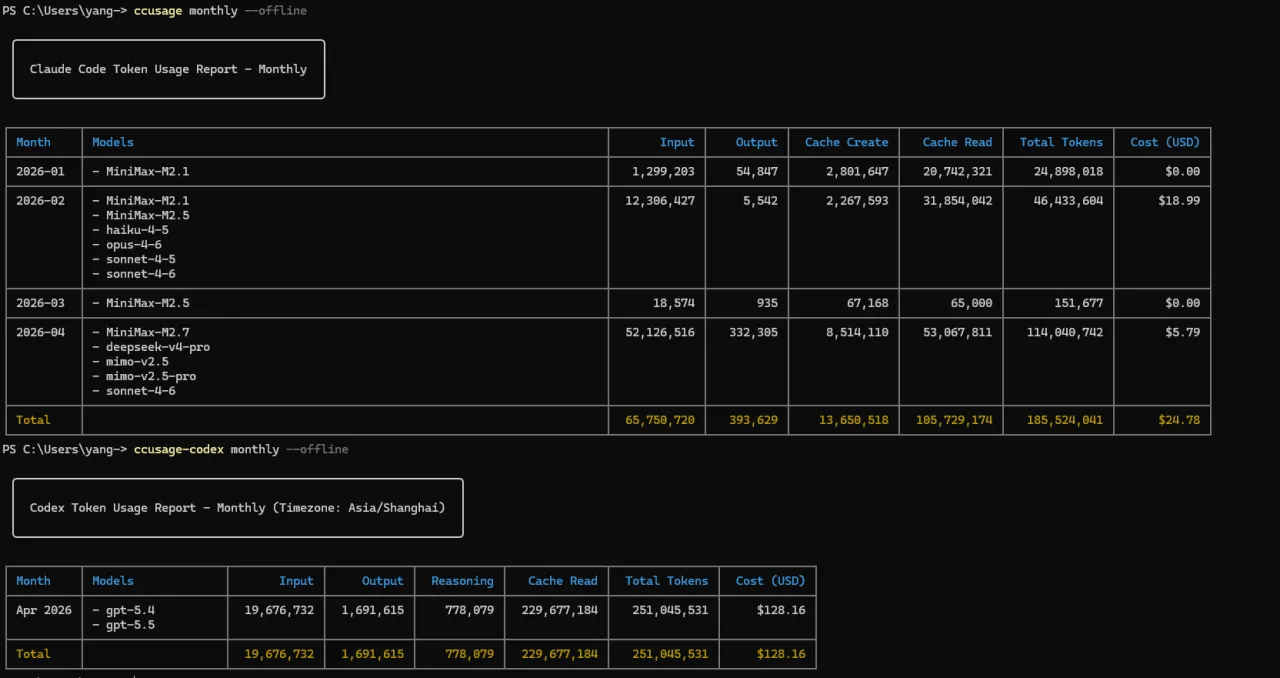 windows消耗量
windows消耗量
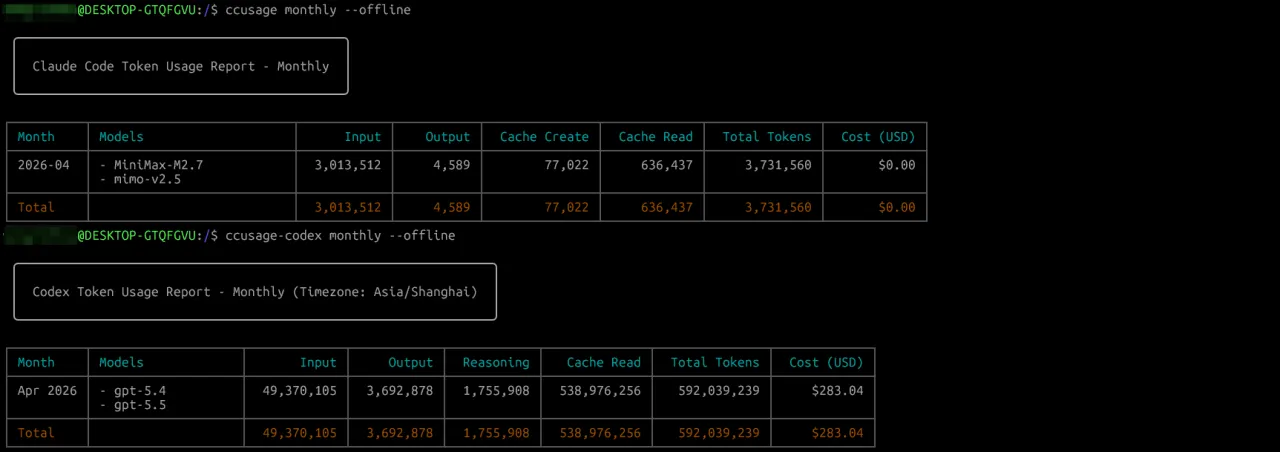 WSL2消耗量
WSL2消耗量
我自己就碰上一个挺典型的情况。第一次看月报,Codex 的总 token 比 Claude Code 高出一大截,第一反应是"最近 Codex 用太凶了"。往下一看才发现根本不是那回事,大头在 Cache Read 上。
也就是说,Codex 的那堆 token,既不是我新输进去的,也不是模型新生成的,而是长会话里反复复用的上下文。仓库说明、系统提示、工具返回、之前读过的文件,这些东西在一个会话里被反复带上,统计数字自然就上去了。只看 Total Tokens,很容易判错案——以为某个工具特别烧,其实人家只是缓存命中高。
这个发现挺受用的。后来再看报表,我不会只盯着总量,顺手会扫一眼这几个:
InputOutputCache ReadTotal - Cache Read还剩多少
这么一对比,哪个月是真写得多,哪个月只是上下文拖得长,心里就有数了。
后来我觉得,ccusage 这种工具特别适合程序员日常自查。不用花什么精力,又能把模糊的感觉变成具体的数字。很多时候我们只是觉得"最近好像用挺多",但这个"挺多"到底是什么量级,不统计永远说不清。有了日、周、月几个维度,很多事就具体起来了。
另外我还挺喜欢它的命令行味儿。想看就开个终端敲一下,不用登网页后台,也不用记项目名、筛选条件。个人用的话,越轻越好,越直接越好。
当然这工具也不是万能的。它更像个人视角的使用记录,不是权威账单。尤其是走第三方接口的,或者模型价格本身就不是标准价,那它显示的费用更适合拿来参考,不适合精确对账。但如果你的目的就是看看趋势、了解自己的使用习惯,那它完全够用了。
最近我对这种小工具越来越有好感。它们不一定解决什么大问题,也不一定非要跟生产力、效率革命挂钩,但只要能把模糊的感受变成清楚一点的数据,就已经挺值了。ccusage 对我来说就这样。装上之后偶尔看一眼,搞清楚自己最近到底怎么在用这些 AI CLI 工具,这件事本身就很有意思。
[DRAFT_RESTORED]
已恢复你上次未提交的评论草稿。
正文草稿仅保留在当前标签页;若浏览器已记住你的身份信息,昵称、邮箱和个人网站可在其他文章页自动回填。