
总算把博客后台里最别扭的一块地方收拾掉了:文章 content 字段原来同时服务两套编辑方式,一套是 Markdown,一套是富文本。表面上看这叫“兼容”,实际写久了就会发现,这种兼容更像是一种长期借债。后台表单复杂,渲染链路分叉,前台要判断内容类型,迁移也不好做。后面每次想改一点功能,都得先问一句:这段逻辑到底是在服务 Markdown,还是在服务旧的富文本?
这次干脆下决心,把它收成一种形态:以后 content 就只表示 Markdown 源文本。
说起来这不是那种“用户一眼就能看出来”的大改动。页面没换皮,交互没大变,甚至很多读者根本不会意识到发生了什么。但对系统本身来说,这种改造很值。因为它把很多隐形复杂度从底层清掉了。
真正麻烦的不是编辑器,而是语义
之前最大的坑,不是后台同时摆了两个编辑器组件,而是它们共用同一个字段。也就是说,数据库里同样叫 content,有时候存的是 Markdown,有时候存的是 HTML。为了让系统知道眼前这段内容到底该怎么处理,又额外依赖了一个 editor_type 字段去分流。
这样做在项目初期没什么问题,甚至很灵活。但一旦文章越来越多,逻辑就会变成这样:
- 后台表单要根据类型切编辑器
- 保存时要做字段映射
- 前台渲染要判断该走 Markdown 解析还是 HTML 直出
- 列表、筛选、订阅流这些外围链路,也会慢慢沾上这个类型判断
最后你会发现,真正难维护的不是某一个组件,而是“同一个字段有两种语义”这件事本身。
所以这次改造的核心,并不是“把富文本编辑器删掉”,而是把 content 的语义重新定义清楚:它以后就只是一份 Markdown。
中间最花时间的部分,其实是迁移策略
定方向很快,真正需要谨慎的是历史文章。
因为数据库里已经有一些文章是富文本写出来的,如果只是粗暴地下线富文本入口,那旧内容要么在后台打不开,要么前台渲染乱掉。这个问题不能靠“以后慢慢改”解决,必须在改造时一次考虑清楚。
我的处理方式是单独写了一条 Artisan 迁移命令,把旧的富文本文章批量转成 Markdown,并在写回前做三件事:
- 识别哪些文章是富文本来源
- 转换前做本地 JSON 备份
- 对表格、内嵌媒体、复杂结构做风险标记
这样至少不是一把梭哈。哪些文章改了、改前是什么、改后是什么,都有落点。就算线上真出了意外,也知道该去哪里找原始内容。
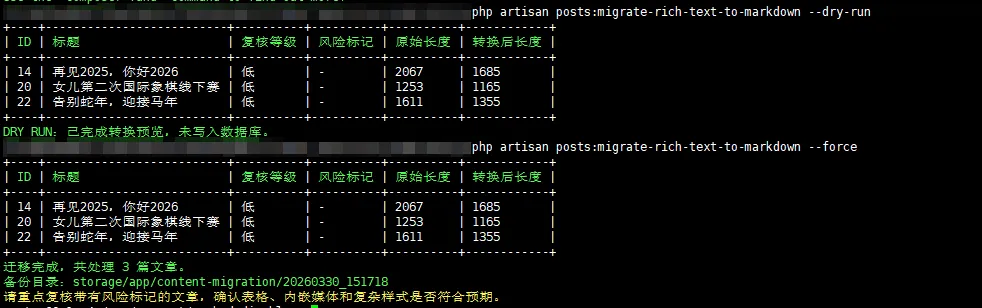
实际迁移的时候,预演结果比我预想得平稳。目标文章数量不多,风险标记也都比较干净。先 dry-run 看结果,再执行正式迁移,这一步做完,心里就会踏实很多。因为你看到的不是“理论上应该可以”,而是“这些具体文章已经被这条命令处理过了”。
这次到底用了什么
这次没有去找一套新的富文本替代方案,后台编辑器直接用的是 Filament 4 自带的 MarkdownEditor。原因其实很朴素:它就是最顺手的那个选择。和现有表单体系是同一套东西,图片上传、表格、代码块、工具栏这些能力也够用,不需要再为了一个编辑器额外接一层状态同步。
真正新增的依赖只有一个:league/html-to-markdown。这个库的作用也很明确,就是把历史文章里那部分 HTML 内容,尽量稳妥地转成 Markdown。因为这次最麻烦的不是以后怎么写,而是过去已经写完的东西,怎么改格式还不出事。
简单列一下这次的技术选型:
- 后台编辑器:Filament 4 官方
MarkdownEditor - 历史内容转换:
league/html-to-markdown - 前台渲染:Laravel 的 Markdown 渲染能力
- 安全处理:统一做 sanitize,旧 HTML 先清洗再输出
这套方案没有引入太多花哨的外部依赖。像这种动到核心字段语义的改造,越靠近框架默认能力,后面越省心。
后台编辑器的核心配置大概长这样,其实就是把入口统一:
MarkdownEditor::make('content')
->label('文章内容')
->required()
->toolbarButtons([
['bold', 'italic', 'strike', 'link'],
['heading'],
['blockquote', 'codeBlock', 'bulletList', 'orderedList'],
['table', 'attachFiles'],
['undo', 'redo'],
])
看到这里基本就能明白,这次的重点不是“做一个新编辑器”,而是让整个系统以后只认这一种内容输入方式。
实现原理不玄乎,就是把链路拉直
这次改造能成立,靠的不是某个插件一键解决,而是把内容从“录入 → 存储 → 渲染”这条链路重新理了一遍。
改造前大概是这样:
- 新文章可能走 Markdown 编辑器
- 另一部分文章走 RichEditor
- 两边最后都写进同一个
content - 前台再看
editor_type决定怎么渲染
问题就在这里:字段名一样,实际含义却不一样。时间一长,表单、模型、前台模板、筛选器、订阅流,全都会被这个分叉牵着走。
改造后我把它压成了一条主链路:
- 后台统一只保留 Markdown 编辑入口
content统一存 Markdown 源文本- 前台统一把 Markdown 渲染成 HTML
- 旧富文本只在迁移阶段做兼容处理
说到底,这次不是“把 A 编辑器换成 B 编辑器”,而是把一份内容从输入到输出的格式统一掉了。只要存储层还是双语状态,前面的表单和后面的渲染迟早还会继续分叉。所以这次真正收口的地方,其实是数据库里的 content 语义。
后台这一层,关键不是换组件,而是换入口
后台表单最直观的变化,当然是只剩下一个 Markdown 编辑器。但实现时我没有一刀切把旧富文本挡在门外,而是在加载编辑页的时候留了一层过渡。
做法不复杂:
- 创建、编辑页面不再主动写
editor_type content统一绑定到MarkdownEditor- 如果当前记录还是旧富文本,就先转成 Markdown,再回填到编辑器里
对应的代码大概就是这样:
->afterStateHydrated(function ($component, $state, $record) {
if (! $record) {
return;
}
if ($record->getAttribute('editor_type') === 'rich_text') {
$component->state(app(RichTextToMarkdownConverter::class)->convert($record->content));
return;
}
$component->state($record->content);
})
这段代码看起来不长,但作用挺大。因为它把“历史兼容”这件事收进了表单加载阶段,编辑者看到的永远只有一个 Markdown 编辑界面,不需要再去理解记录背后原本是哪种格式。兼容逻辑继续存在,但不再暴露给人。
转换器真正做的事,不只是 HTML 转 Markdown
一开始我也想得比较简单,觉得把 league/html-to-markdown 接上去,事情大概就差不多了。后面一跑真实数据才发现,库只是帮你把结构翻译过来,真正决定迁移质量的,是后面那层整理动作。
这个库擅长的是结构映射,比如:
<h2>变成##<strong>变成**<ul><li>变成-<img>变成
这些当然很重要,但它解决的是“能转”。而线上文章真正关心的是“转完像不像正常人写的”。尤其是图片、空行、复杂嵌套这类细节,不补一层规范化,最后很容易变成 technically 正确、视觉上难受。
所以我在转换器外面又做了两件事:
- 先做风险探测,把表格、iframe、内联样式、自定义 class 这种内容标出来
- 再做 Markdown 规范化,把空行、图片边界之类的排版细节顺一遍
比如后来修的那个图片问题,本质上就是补了图片前后的段落边界:
$markdown = preg_replace('/(?<!\n)(!\[[^\]]*]\([^)\n]+\))/', "\n\n$1", $markdown) ?? $markdown;
$markdown = preg_replace('/(!\[[^\]]*]\([^)\n]+\))(?!\n)/', "$1\n\n", $markdown) ?? $markdown;
这种代码谈不上多优雅,但很实用。因为内容迁移本来就不是只讲理论正确,它最后还是得落到“前台显示是不是顺眼”。
再往前一步,前台渲染也被统一收口了。Markdown 就走 Markdown 渲染,旧富文本只在过渡阶段走安全清洗:
if ($editorType === 'rich_text') {
return Str::sanitizeHtml($content);
}
return Str::sanitizeHtml((string) Str::markdown($content));
写到这里我反而觉得,这次最值的不是某一段代码,而是终于把“谁负责输入、谁负责转换、谁负责渲染”这件事理清楚了。
看起来已经成功了,结果还是被一张图片教育了
这种数据迁移最有意思也最烦人的地方就在这里:大方向都对,通常最后出问题的,反而是很具体、很小的一种内容形态。
这次我碰到的就是图片换行。
有一篇文章里,图片是夹在一段正文中间的。富文本转 Markdown 之后,图片语法被保留了下来,但没有自动拆成独立段落,于是前台渲染出来时,图片和前后的文字粘在一起,显示就不正常。
这个问题不算大,但特别典型。它提醒我一件事:内容迁移不是只有“能不能转”,还有“转完之后像不像人写的”。Markdown 本来就很依赖段落结构,如果图片还留在行内,渲染结果即使没报错,视觉上也还是坏的。
后面就给转换器补了一层规范化逻辑,专门处理这种图片前后缺少断段的情况。说白了就是:遇到图片语法,不要让它黏在正文里,前后该补空行就补空行。然后再加一条针对这个场景的测试,保证“正文 + 图片 + 正文 + 图片”这种内容以后不会再回归。
这次改造真正清掉的,是到处散落的判断
内容迁移只是其中一块,更省心的其实是后续代码的收口。
后台创建页、编辑页,不再需要显式写入编辑器类型;文章表单统一只保留 Markdown 编辑器;文章列表里跟编辑器类型有关的筛选和展示也可以删掉;前台渲染则统一收口到一个渲染入口,旧富文本只作为兼容兜底存在,直到数据彻底迁完为止。
这种收口带来的好处很直接:
- 后台表单少了一层条件分支
- 前台渲染链路更稳定
- 后续做缓存、统计、订阅这些功能时,不用再反复判断内容来源
content字段终于只表达一件事
很多时候系统复杂,不是因为业务有多复杂,而是因为同一个概念承担了太多历史责任。把这些责任拆开、迁走、收口,代码就会安静下来。
 前台样式确认
前台样式确认
 后台管理系统确认
后台管理系统确认
上线这一步,我反而比开发更小心
代码改完不算结束,真正要命的是上线顺序。
因为这次不仅有代码调整,还有内容迁移和字段删除。如果顺序错了,比如先把数据库里的 editor_type 删了,再去处理那些还没迁移完的富文本文章,风险会一下子放大。系统虽然不一定立刻报错,但你已经失去了区分旧内容来源的依据。
所以这次线上流程我刻意拆成了几段:
- 先发布代码
- 先执行内容迁移
- 抽查前台和后台表现
- 最后才删除
editor_type
这个顺序看起来保守,但线上环境里,保守往往就是效率的一部分。因为你不是在追求“命令更短”,你是在追求“出事时还有退路”。
好在最后整套流程跑下来比较顺。迁移完成,前台样式正常,后台编辑内容也确认已经是 Markdown 形态,整个 content 字段终于从“双语状态”收敛成了单语状态。
这次改造没有做出什么新功能,但我挺喜欢
我现在越来越觉得,系统里真正舒服的改动,很多都不是新加了什么,而是终于可以删掉什么。
删掉双编辑器。
删掉多处 editor_type 判断。
删掉“这段内容到底是什么格式”的心智负担。
最后留下来的,不只是一个更轻的后台,还有一个更清楚的数据模型。
这种改动写进周报里可能不够热闹,放到发布说明里也不算显眼,但如果以后还要继续在这个博客上叠功能、调体验、做优化,那它应该算是一块还挺关键的地基。
写到这里,反而会觉得这次最大的收获不是“把富文本迁移成 Markdown”本身,而是又确认了一遍:技术债最怕的不是重,最怕的是它被包装成“兼容性很好”。很多时候,真正的兼容,不是让两套东西一直并存,而是在合适的时候,认真把旧路收掉。
[DRAFT_RESTORED]
已恢复你上次未提交的评论草稿。
正文草稿仅保留在当前标签页;若浏览器已记住你的身份信息,昵称、邮箱和个人网站可在其他文章页自动回填。